Splitting and combining
match finds and tags only the first match in each sequence. To find all
pattern matches, Sequence Operations Language (SOL) provides the match split
operation. It first finds all non-overlapping matches and then splits
sequences before each match.
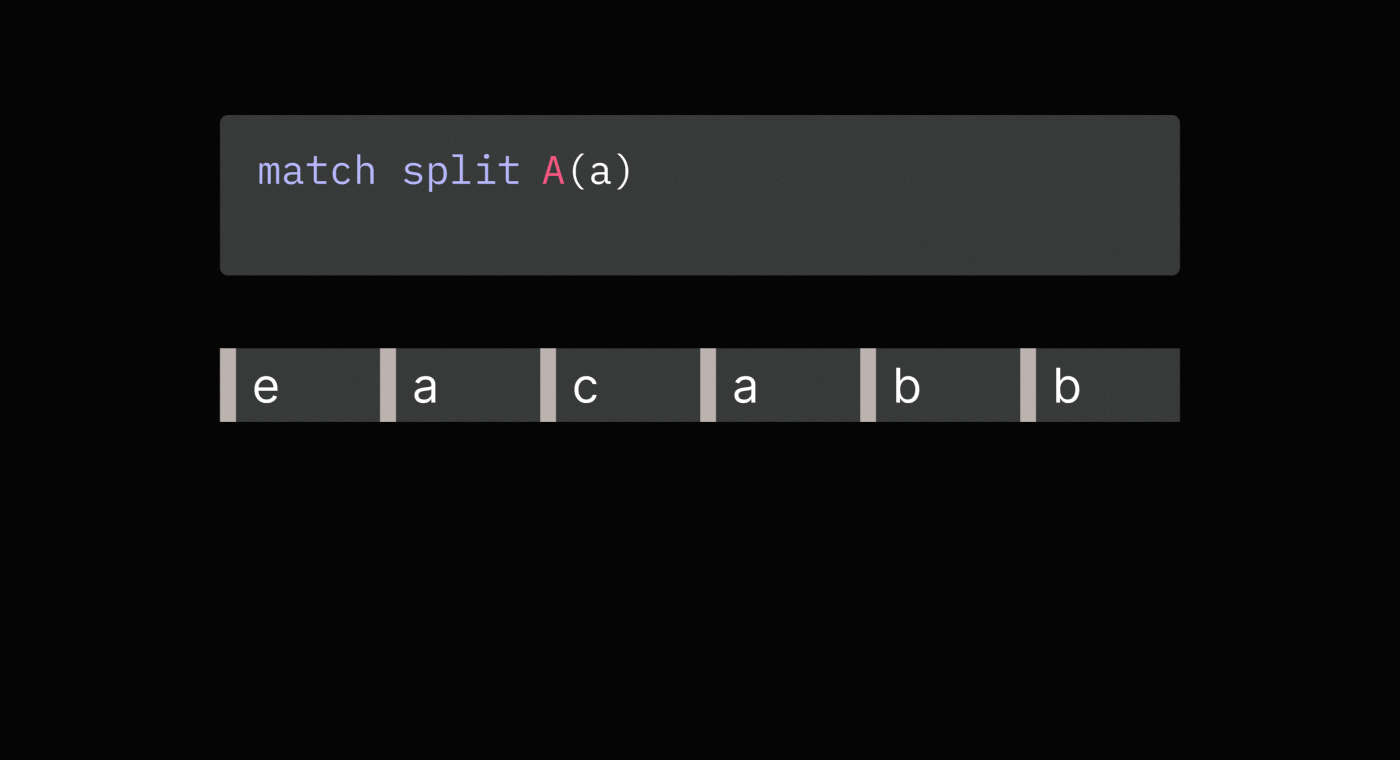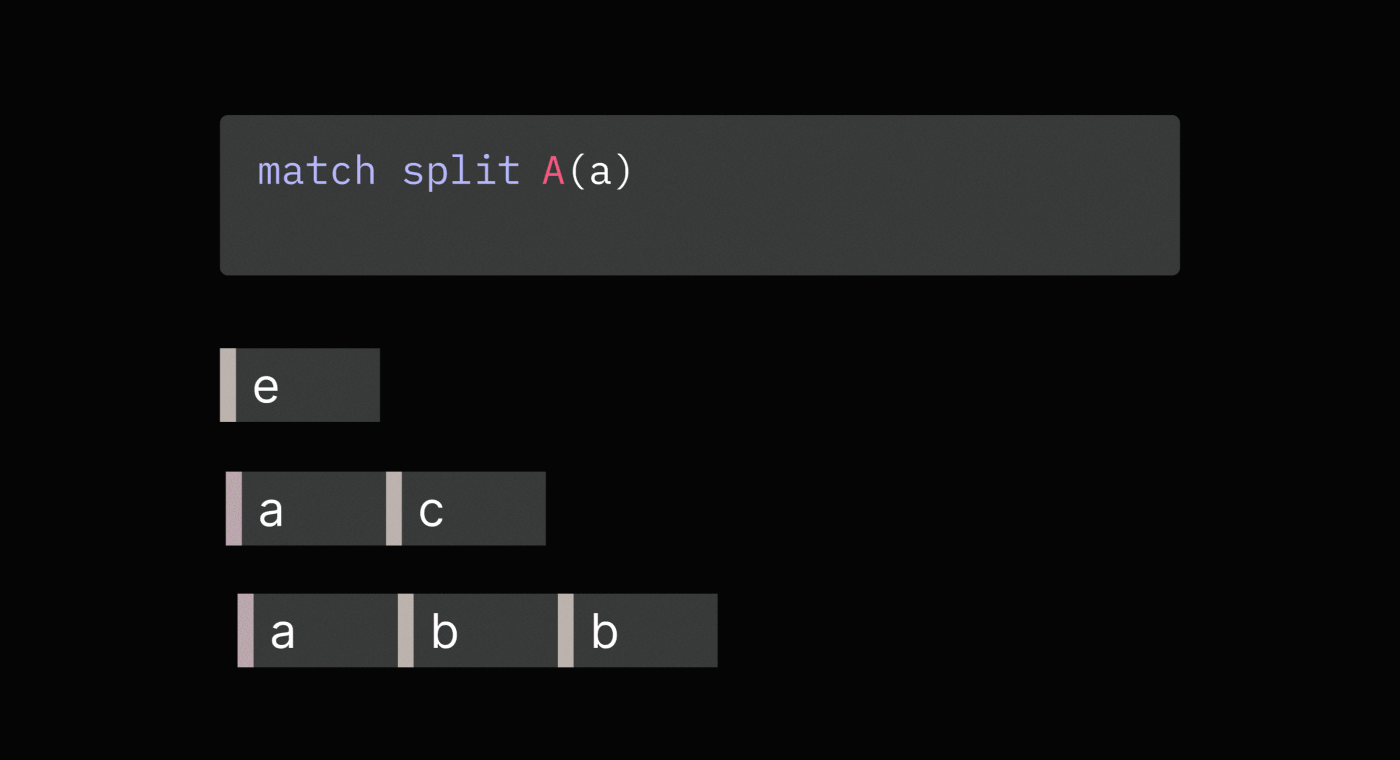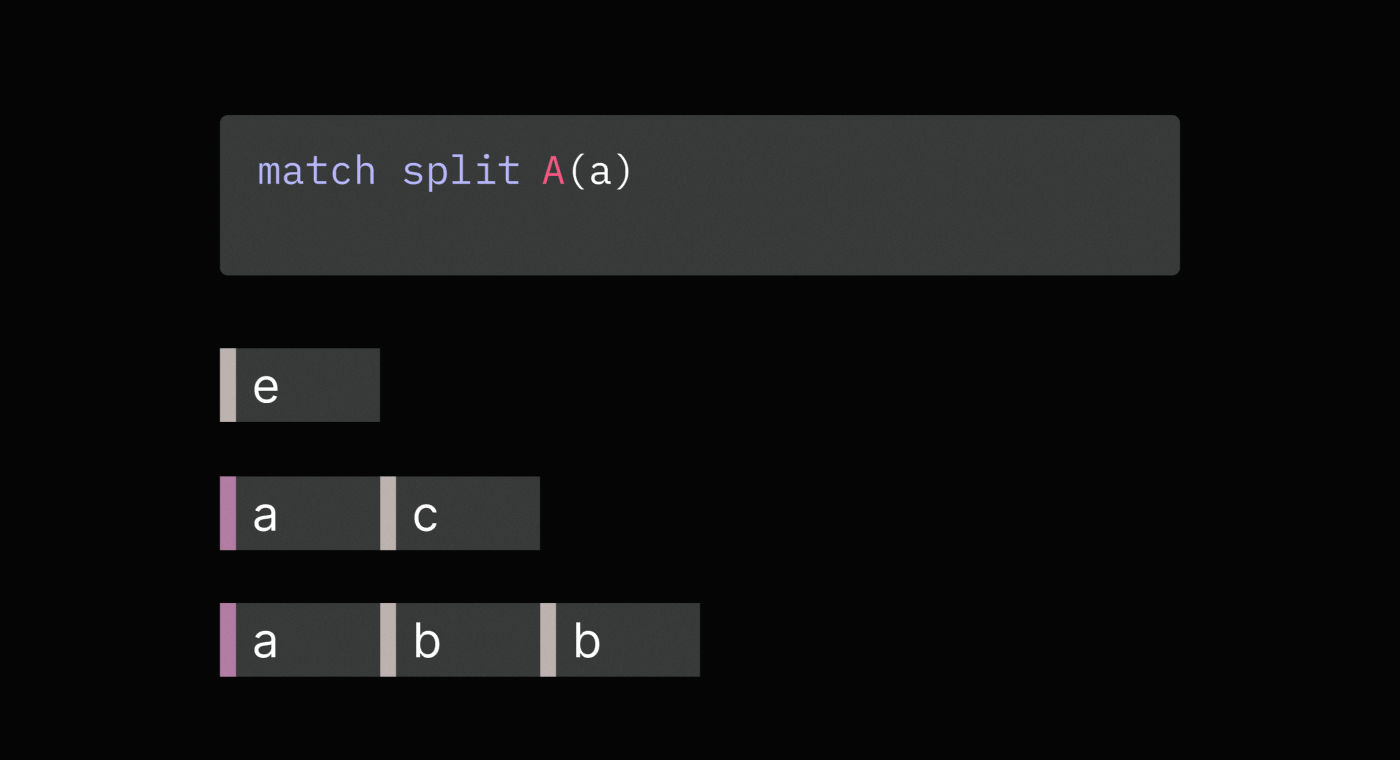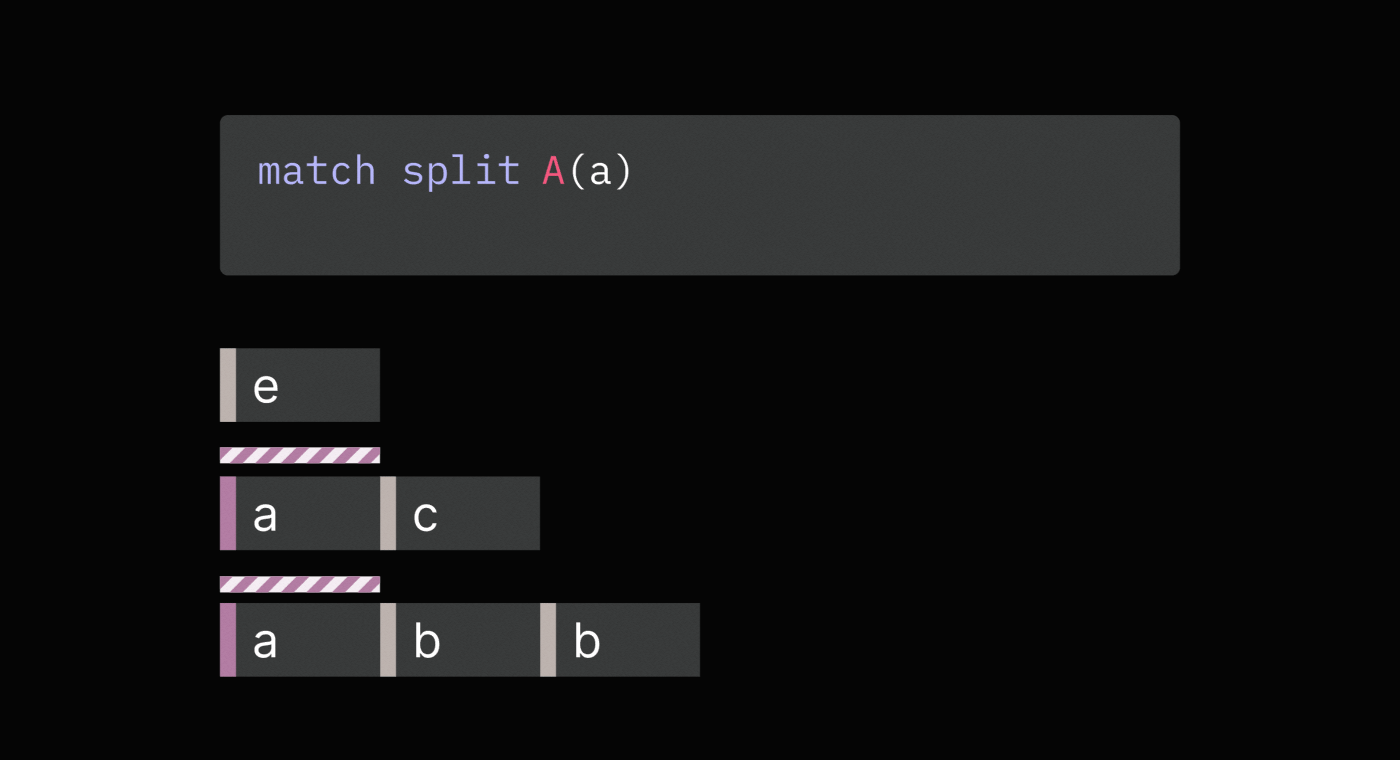
Splitting on each match avoids having more than one tag by the same name in a sequence, which makes it easier to reason about and work with tags.
match split is essential for 2 common use cases. The first one is
“sessionization” - breaking user activity into shorter “sessions” of interest,
for example:
// Find what users do after every visit to "search_page"
match split search_page
// Split into sessions based on 1 hour of inactivity
match split Session()+
// Require duration between the last event of each match and the next event to be over 1 hour
if duration(Session[-1], SUFFIX[0]) > 1h
Note that events before the first match get split into its own sequence and are
labelled with a PREFIX tag. Events between matches stay together with the
prior match and are labelled as SUFFIX.
Resulting sequences are also assigned 2 implicit sequence dimensions:
match_count- the number of matches in a sequence before the split (not counting the optionalPREFIXsequence)match_index- index of a match in a sequence before the split, starting from 1 (the optionalPREFIXsequence gets the index of 0).
The second common use case for using match split is labelling all matches,
working on them in separate sub-sequences and then merging them back together.
The final step of putting sub-sequences back together is done in SOL using
combine operation.
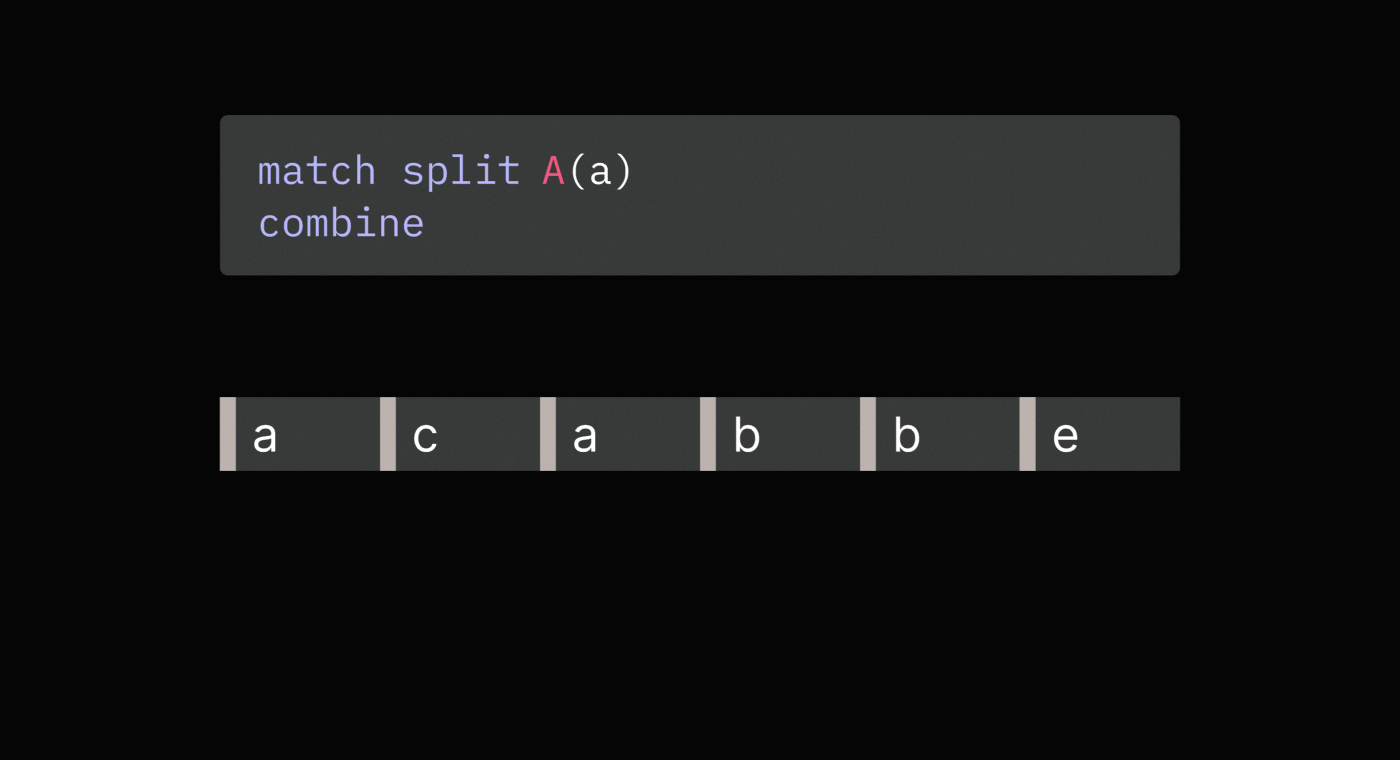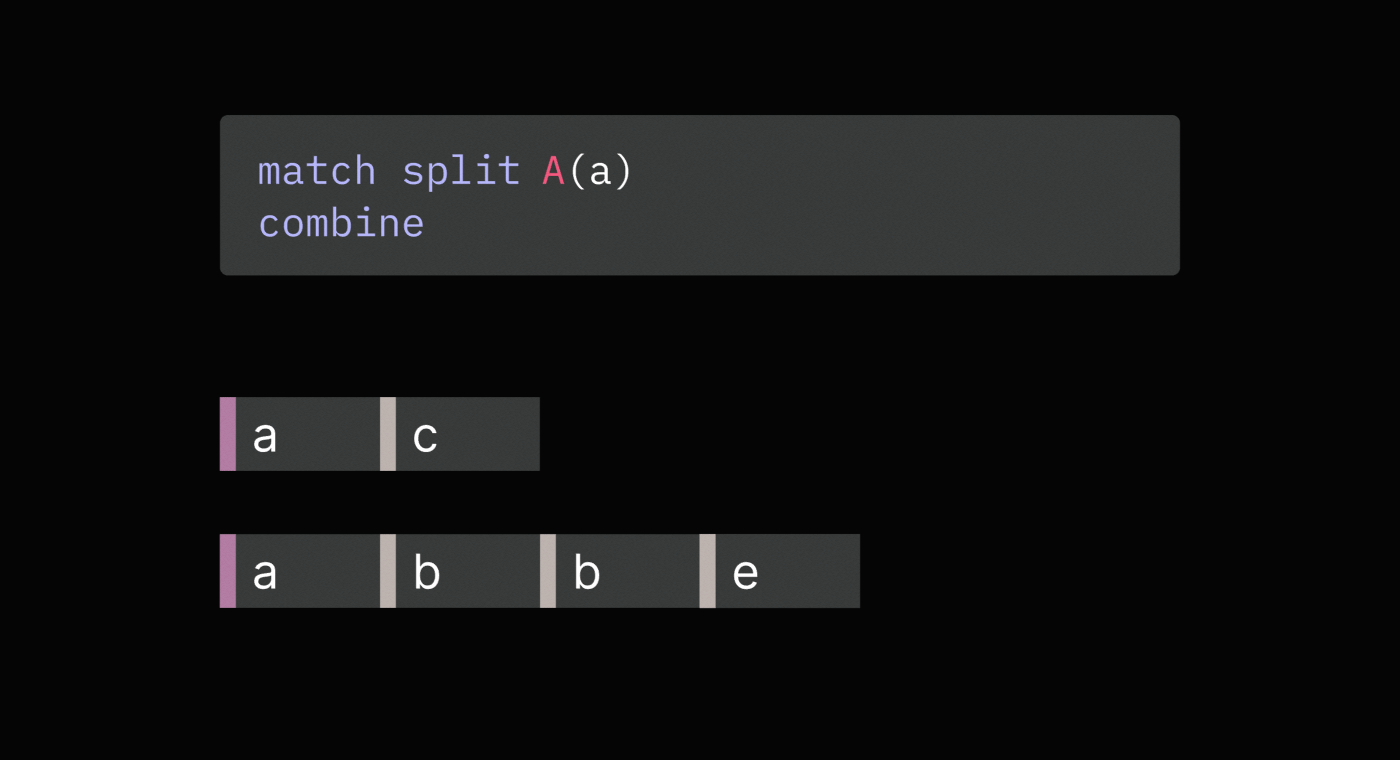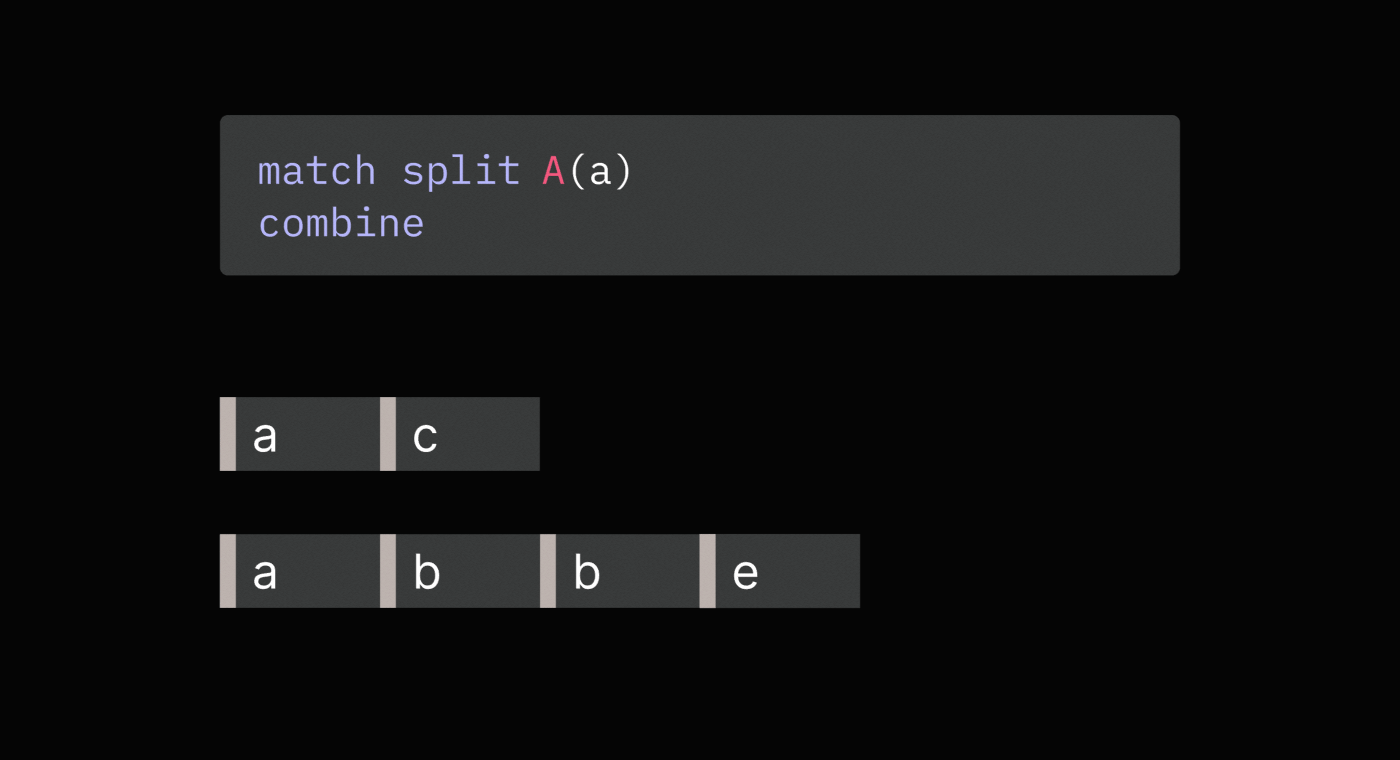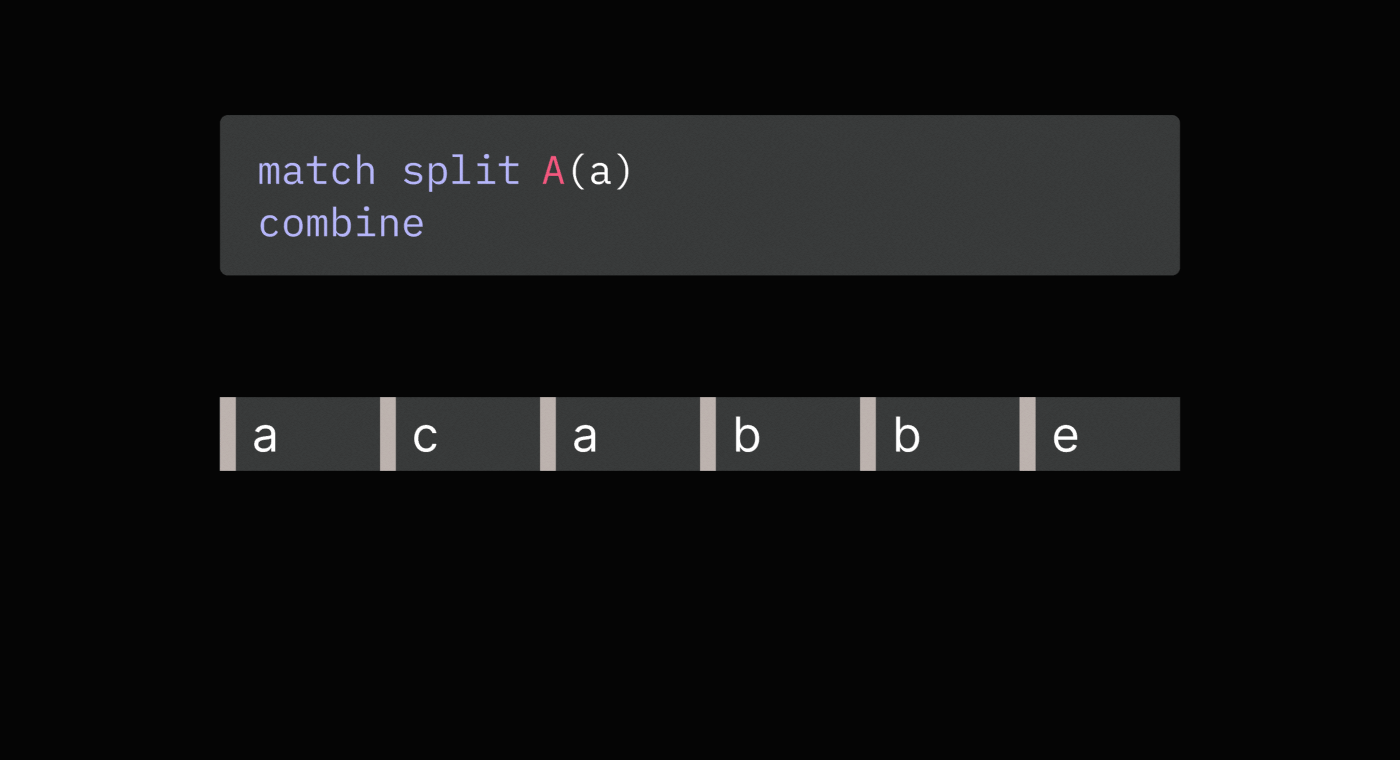
Here is an example:
// Compute total spend by a user across all purchases
match split purchase
set spend = purchase.price
combine total_spend = sum(spend)
// Now user sequences have a "total_spend" sequence dimension
combine deletes sequence dimensions, which were set or updated after the
previous match split unless it is provided with aggregation logic. In the
example above, spend dimension is deleted after merging the sequences and
instead a new aggregated total_spend dimension is created. You can think of it
as scoping sequence dimensions to the match split / combine query block.
Other common situations for using combine are removing and renaming events and
coarsening sequences, which are discussed in detail in the
“Replacing” section.
Note that combine removes previously assigned tags to avoid having multiple
tags by the same name on merged sequences.
A SOL query can have nested match split and combine operations such as:
match split A...
...
match split B...
...
combine
...
combine
In this case you can think of splitting and combining working as a stack, with
each combine unwinding only the latest match split.