Matching and tags
Overview
The most important concept in sequence analytics is matching. It allows you to find complex event patterns based on the order of events and to label them, so you can work with them later in your query. Matching is similar to using regular expressions, but works on sequences of events instead of strings of characters and has a more user-friendly and readable syntax.
In Sequence Operations Language (SOL), matching is done using the match
operation.

match takes a match pattern as an argument. The simplest match pattern
consists of a single event name, for example:
// Match the first event called “purchase”
match purchase
To match a pair of consecutive events you need to put a >> connector between
them:
// Match the first “product_page” directly followed by "purchase"
match product_page >> purchase
You can use “quantifiers” from regular expressions to match a range of events. They have to immediately follow the event they apply to:
// Match 1 or more “product_page” events followed by "purchase"
match product_page+ >> purchase
// Available quantifiers:
// * - match zero or more times
// + - match one or more times
// ? - match zero or one time
// {n} - match exactly n times
// {n,} - match at least n times
// {,n} - match at most n times
// {n,m} - match from n to m times
To match a pair of events with any number of any events in between them, you can
use a “wildcard” *:
// Match "search” followed by "purchase" with any number of any events in between
match search >> * >> purchase
You can specify included events (via |s) and excluded events (via ^ and
,s) of event names in match patterns:
// Match "search_page" eventually followed by a "purchase_movie" or "rent_movie" event without having "home_page" or "favorites_page" events in between
match search_page >>
(^home_page, favorites_page)* >>
Conversion(purchase_movie | rent_movie)
In this case event names have to be enclosed in ().
You can match to the beginning or to the end of sequences:
// Match sequences, which start with a "login" event and end with a "logout" one
match start >> FirstEvent(login) >> * >> LastEvent(logout) >> end
It is important to understand that matching doesn’t filter out sequences without
matches, only assigns tags to the matched ones. Filtering to sequences with
matches can be done with filter MATCHED.
Tags
There are 3 types of SOL variables:
event dimensions,
sequence dimensions, and tags. A tag
is a label attached to one or more contiguous events of interest, which is
created by tagging events while executing match. Tags are used to access
events of interest and their dimensions. They have names and are visualized by
lines above events. Tags are automatically created when matching events by name
as in the examples above - they are assigned the same names as underlying
events. Sometimes it is important to explicitly name a tag. To do this you need
to enclose event names in parentheses and to add tag's name immediately before
the opening bracket:
// Label consecutive “product_page” events with a "ViewProducts" tag and "purchase" event with a "Buy" tag
match ViewProducts(product_page)+ >> Buy(purchase)
Tags can be used to specify conditions on the match patterns in the if clause
of the match operation as described in
“Conditions and filtering.”
match is used to create tags, which are used by subsequent SOL operations to
access, transform and remove underlying events of interest.
Tags are ephemeral: each new match operation completely removes tags from the
previous match.
After each match, in addition to user-defined tags SOL also creates several
implicit tags (not case sensitive), which provide convenient access to all
events around the match:
PREFIX- sub-sequence of all events before the first matched eventMATCHED- sub-sequence of all matched eventsSUFFIX- sub-sequence of all events after the last matched event.
There is one more implicit tag, SEQ, which is always available to SOL
operations (even without prior matching) and encompasses all events in a
sequence.
Tags containing more than one event support array operations as follows:
- Tags are ordered lists (vectors, 1d-arrays) of events and can be sliced to
access sub-lists of events using Python list syntax:
Tag[0],Tag[-1],Tag[2:-2]. - Event dimensions are referenced by
Tag.event_dimsyntax and return a list of event dimension values (“broadcasting”).
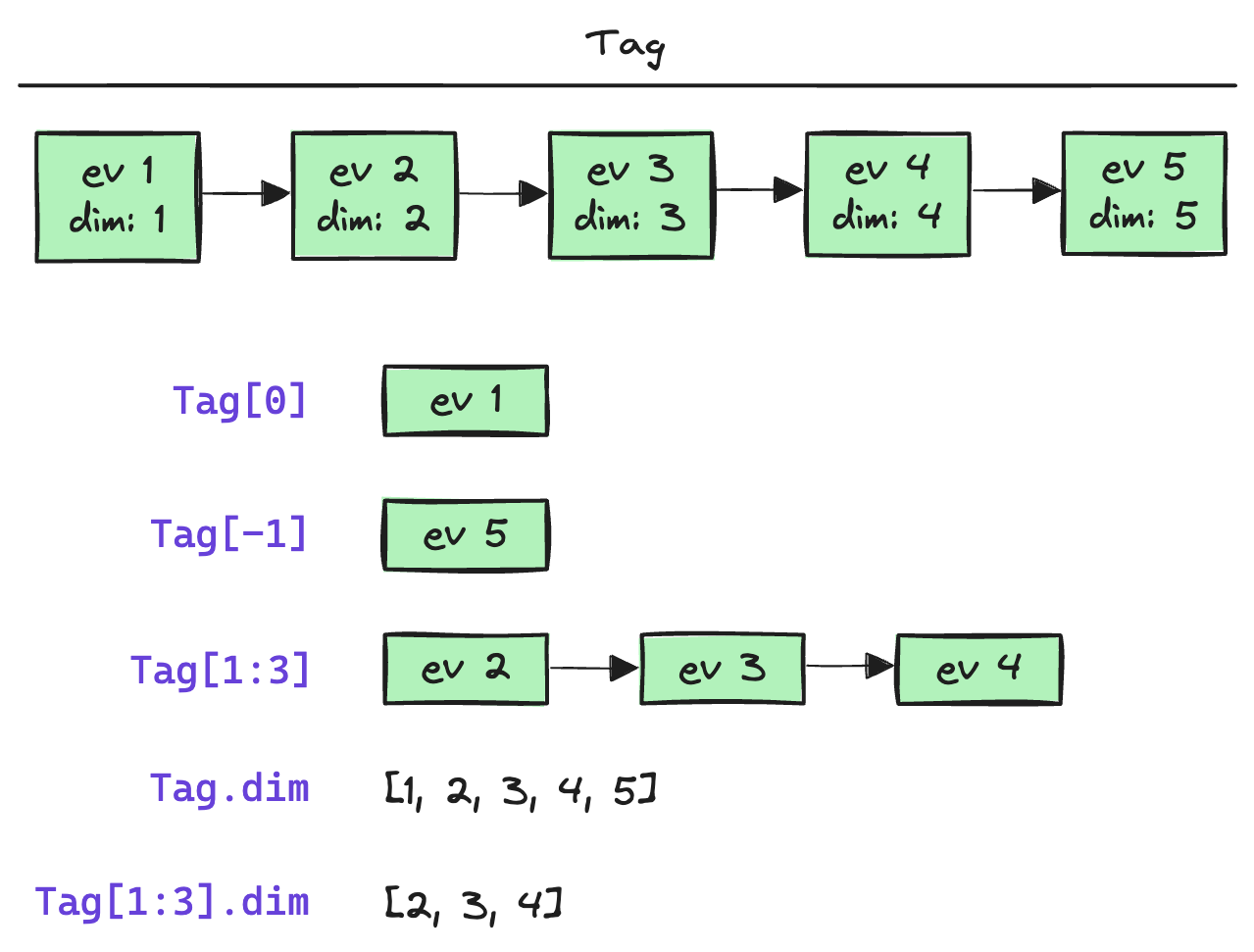
More details on how tags work:
- Tag names must be unique within a sequence, so matching multiple instances of
a tag within a sequence requires splitting sequences at each match using
match split. - Tags can’t overlap (except the implicit
SEQandMATCHEDtags): new match and combine operations remove all prior tags, replace removes tags which become ill-defined after the operation. - Tags and sequence dimensions are referenced in the same way in SOL. In most
cases it is clear which one is referenced (for example, sequence dimensions
can’t be followed by
.) but if not, then interpreting as a tag takes priority. - In visualizations, tags can be treated as an atomic unit and can be collapsed into one event with the tag name displayed as the "event name."
Matching algorithm details
Matching is performed left-to-right and event-by-event. When deciding how to match each event, the algorithm uses the following order of preference:
- (Path 1) Start populating the next tag
- (Path 2) Add to the current tag
- (Path 3) Finalize match without event
To decide whether to assign the event to (Path 1) or (Path 2), the conditions are evaluated as follows:
- The
ifclause is broken into simpler conditions connected byand - Each condition is assigned to one of the tags it references, which is the farthest in the match pattern
- For (Path 1) conditions for the next tag are evaluated
- for path (2) conditions for the current tag are evaluated
(Path 3) is possible if all remaining tags in the match pattern are optional.
The matching process ends after finding the first acceptable match. If the algorithm can’t find a match on the first pass, it backtracks and adds to the current tag (Path 2) instead of starting to populate the next tag (Path 1) at the last possibility to do so. This makes certain match patterns much longer to compute, using O(n^2) instead of O(n) speed.
For performance reasons, backtracking should be avoided if possible. In most cases slow match patterns can be written to avoid backtracking.
After successfully completing a match, the three implicit tags PREFIX,
SUFFIX, and MATCHED (described above) are added to the sequence.
Due to how matching works, the final result:
- has no overlaps or gaps between tags - each event has to belong to one of the
tags in the match pattern,
PREFIXorSUFFIXtags (only exceptions are implicitMATCHEDandSEQtags) - uses “lazy” matching for the tags in the middle of the match patten (prefers to jump to the next tag rather than extending the current one)
- uses “greedy” matching for the tags on the edges of the match pattern (prefers to extend current tag rather than finalizing the match)
Special behaviors
-
“Until” conditions: The truth value of certain
ifconditions only needs to be evaluated at the end of a successful tag match and not for every partial subsequence. For example:if Tag[-1].dim = 'value'if sum(Tag.dim) > 100if any(Tag.dim) = 'value'
We call these “until” conditions (as opposed to “while” conditions). The match algorithm automatically detects such "until" conditions, and evaluates them only when transitioning to the next tag (Path 1)) or when finalizing the match (Path 3), leading to more efficient computation.
-
Zero-matching: when matching optional tags (with a
*,?or{,m}quantifier) and evaluating them on zero matched events, conditions for that tag are skipped and NOT evaluated. This is done to support operations likematch A >> * >> B? if duration(A, B) < 1mininstead of having to be more explicit:match A >> * >> B? if not(B) or duration(A, B) < 1min. -
Optional matching: it is usually preferred that tags with the
?quantifier match events rather than not, so to produce expected behavior matching?tags follows several special rules:- they are first evaluated for matching one event and, only if that fails, proceed to match zero events
- if there are several optional tags (with a
*,?or{,m}quantifier) in a row,?tags take priority. For example,match T0(a) >> T1()* >> T2(b)? >> T3(){,5} >> T4(c)?operation after matchingT0when evaluating each following event will first try to matchT2, thenT4, thenT1and thenT3. - A side-effect is that starting a match pattern with the
?tag will usually skip it unless it matches the very first event in the sequence. To avoid this behavior add*before it into the match pattern:* >> ?.